Difference between revisions of "20.109(S16):Flow cytometry and paper discussion (Day7)"
Noreen Lyell (Talk | contribs) (→Introduction) |
MAXINE JONAS (Talk | contribs) (→Part 2: Analyze flow cytometry data) |
||
| (35 intermediate revisions by 2 users not shown) | |||
| Line 7: | Line 7: | ||
We hope that you’ll leave lab today with a sense of accomplishment, after inspecting your raw flow cytometry data and then calculating NHEJ repair values. Unfortunately or excitingly – depending on your perspective – it turns out in scientific research that the hard work is just beginning once the data is quantified! Interpreting the data and drawing (sometimes tentative) conclusions requires deep reading and thinking – a process that shouldn’t be rushed. | We hope that you’ll leave lab today with a sense of accomplishment, after inspecting your raw flow cytometry data and then calculating NHEJ repair values. Unfortunately or excitingly – depending on your perspective – it turns out in scientific research that the hard work is just beginning once the data is quantified! Interpreting the data and drawing (sometimes tentative) conclusions requires deep reading and thinking – a process that shouldn’t be rushed. | ||
| − | Now is the time to clearly understand the nature of the flow cytometry controls that you will examine. For each cell population, you prepared two DNA mixtures: (A) intact | + | Now is the time to clearly understand the nature of the flow cytometry controls that you will examine. For each cell population, you prepared two DNA mixtures: (A) intact pMAX_mCherry plus intact pMAX_EGFP, and (B) intact pMAX_mCherry plus damaged pMAX_EGFP_MCS. The re-circularization of pMAX_EGFP_MCS (minus the nonsense insert) will be our most direct readout of how much repair occurred. In this simplest view, broken DNA = no fluorescent signal, and repaired DNA = green fluorescent signal. However, it is important to consider the possibility that one cell population simply took up more plasmid DNA than another. In more technical terms, what if the ''transfection efficiency'' is higher for one cell type than for the other, and therefore the repair rate artificially appears higher? To control for this, we co-transfected with intact pMAX_mCherry, which serves as a transfection control. Using the transfection control data, we will normalize for differences in DNA uptake. It is also important to think about the uptake of pMAX_mCherry compared to the uptake of pMAX_EGFP_MCS. What if the plasmids are taken up at different frequencies, or successfully expressed at different frequencies and/or signal intensities? Here is where the dual intact control is useful. It shows us the typical ratio of mCherry:EGFP uptake and expression, which we can use as a secondary normalization. Note that we use pMAX_EGFP as a control rather than pMAX_EGFP_MCS, because the latter will have very low expression that is not representative of the repaired construct: the nonsense insert separates the promoter and gene by too great a distance for robust expression. |
Putting all of the above information together, the NHEJ repair frequency equation can be determined in three steps: | Putting all of the above information together, the NHEJ repair frequency equation can be determined in three steps: | ||
| Line 15: | Line 15: | ||
::*MFI is mean fluorescence intensity ''or'' median fluorescence intensity | ::*MFI is mean fluorescence intensity ''or'' median fluorescence intensity | ||
<br> | <br> | ||
| − | :(2) Normalized | + | :(2) Normalized EGFP expression <math>\qquad ={RAW_{EGFP} \over RAW_{mCherry}}\qquad</math> = "NORM" |
<br> | <br> | ||
| − | :(3) Reporter expression percent <math>\qquad ={NORM_{ | + | :(3) Reporter expression percent <math>\qquad ={NORM_{EGFP.damaged} \over NORM_{EGFP.intact}}\qquad</math> = NHEJ repair value |
<br> | <br> | ||
| − | + | First, reporter expression for mCherry and EGFP alike will be calculated by multiplying percentage of positive cells by fluorescence intensity (FI). We have a choice of whether to use mean, geometric mean, or median fluorescence intensity. Median fluorescence is least susceptible to being influenced by a few outliers, while geometric mean is generally more appropriate for log scale data than arithmetic mean. For normally distributed populations, all three values should be pretty similar. In practice, we have found that while mean and median FI are very different values, after normalization the ultimate NHEJ repair values are quite similar, so we will use the mean value. | |
| − | + | The second step is to calculate the ratio of EGFP to mCherry reporter expression for each sample. The final step is to divide the damaged-EGFP:mCherry ratio by the maximal possible “repair,” namely the intact-EGFP:mCherry ratio. Convince yourself that this parameter essentially provides the fraction of pMAX_EGFP_MCS repaired. | |
| − | + | Most of your time today will be spent at the computer, quantifying your flow cytometry data. Use this time to get a strong start on the data analysis for your Systems engineering research article. On M2D9, we will use statistics to further analyze our data. | |
| − | ==== | + | ==Protocols== |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| + | ===Part 1: Paper discussion=== | ||
| − | ''' | + | We will start today with a discussion of the Dietlein ''et al.'' [[Media:M2D7 Cancer Discovery-2014-Dietlein-592-605.pdf |research article]]. In their research, the authors completed a screen to examine 1319 cancer-associated genes from 67 cell lines to identify cancer-cell specific mutations that are associated with DNA-PKcs dependence or addiction. A paradox exists in cancer as whole genome sequencing has revealed that the cells of many tumor types have mutations in genes necessary for DNA repair. These mutations are responsible for cells becoming cancerous, but are also detrimental because, just like normal cells, cancer cells must divide to survive. Thus, a cancer cell will develop an ‘addiction’ to a DNA repair pathway – specifically, a pathway different from the one with the mutation that caused the cell to generate a tumor. Recent cancer therapies seek to exploit this addiction by targeting the intact pathway used by the tumor cells to repair DNA damage due to intrinsic breaks that occur during replication. In addition, the effectiveness DNA damage induced by chemotherapy treatment may be enhanced by also disrupting the functional repair pathways of tumor cells. The [[Media:M2D7 DNA repair addiction.pdf |review article]] by Shaheen ''et al.'' provides further information on repair pathway addiction as a target in cancer treatment. |
| − | + | Our paper discussion will be guided by all that you have learned about how to write a cohesive story that clearly reports the data and provides strong support for the conclusions made about the data. '''During the paper discussion, everyone is expected to participate - either by volunteering or by being called upon!''' | |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | ===== | + | ====Introduction==== |
| − | + | ||
| − | + | Remember the key components of an introduction: | |
| − | + | *What is the big picture? | |
| − | + | *Is the importance of this research clear? | |
| − | + | *Are you provided with the information you need to understand the research? | |
| − | + | *Do the authors include a preview of the key results? | |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | ===== | + | ====Results==== |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | Carefully examine the figures. First, read the captions and use the information to 'interpret' the data presented within the image. Second, read the text within the results section that describes the figure. | |
| − | + | *Do you agree with the conclusion(s) reached by the authors? | |
| − | + | *What controls are included and are they appropriate for the experiment performed? | |
| − | + | *Are you convinced that the data are accurate and/or representative? | |
| − | + | ||
| − | === | + | ====Discussion==== |
| − | + | Consider the following components of a discussion: | |
| − | * | + | *Are the results summarized? |
| − | * | + | *Did the authors 'tie' the data together into a cohesive and well-interpreted story? |
| − | * | + | *Do the authors overreach when interpreting the data? |
| + | *Are the data linked back to the big picture from the introduction? | ||
| − | + | ===Part 2: Analyze flow cytometry data=== | |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | In the previous laboratory session, you learned how the gates are established in flow cytometry. This very important step is necessary in enabling you to distinguish and count the specific cell populations within your samples. Today you will analyze the numerical data, or counts, that were collected for your transfection conditions based on the mCherry and EGFP gates. | |
| − | + | Before you calculate the frequency of DNA repair that occurred in your samples, examine the data obtained in Spring 2015 to acquaint yourself with calculations discussed in prelab. The spreadsheet below shows a template used to calculate the NHEJ repair efficiency using the EGFP:BFP reporter system employed by students previous to this semester. Use the data in the spreadsheet to answer the questions below. | |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | [[Image:S14M2_worksheet-example.png|thumb|center|750px|'''Sample NHEJ calculator screenshot with Spring 2015 flow cytometry data.''' Mean (top) and median (bottom) fluorescent values were used to calculate NHEJ efficiency (%) in the wild-type K1 and Ku70 mutant xrs6 cell lines. "GFP/BFP" indicates cells were co-transfected with pMAX_EGFP (transfection control) and pMAX_BFP (intact reporter) to determine 100% DNA repair. "GFP/cutB" indicates cells were co-transfected with pMAX_EGFP (transfection control) and damaged pMAX_BFP_MCS (damaged reporter) to determine repair efficiency compared to 100% DNA repair (GFP/BFP value).]] | |
| − | [[Image:S14M2_worksheet-example.png|thumb|center| | + | |
| − | + | #To test yourself, use the numbers provided in the sample spreadsheet to calculate the NHEJ efficiency with the median fluorescent values by hand. | |
| + | #*Include your math in your notebook. | ||
| + | #First, you will create a template in Excel that will enable to quickly determine the values for your samples. | ||
| + | #*Feel free to use the format of the sample NHEJ calculator. | ||
| + | #*Enter the median values from the sample spreadsheet to test your template. | ||
| + | #[[Image:Sp16 M2D7 plot statistics.png|thumb|right|500px|'''Flow cytometry plot statistics summary.''']]Now let's look at the data collected using your conditions. | ||
| + | #*Open the PDF posted to the M2D7 Discussion page named "Instructor FC plots" and the sample key named "Instructor FC sample key" and find the plot for sample #8 (M059K cells co-transfected with pMAX_mCherry and pMAX_EGFP). At the bottom of the page you should see a table similar to the one shown at the right. | ||
| + | #*The values in this table are the counts that were measured for this sample. Consider the following: | ||
| + | #** #Events = the number of cells counted based on the gate established (''i.e.'' the number of red cells is based on the mCherry gate) | ||
| + | #**%Parent = the percentage of cells in a given population (''i.e.'' the number of red cells within the live cell population) | ||
| + | #**FITC-A = filter used to 'see' green cells | ||
| + | #**PE-Cy5-5... = filter used to 'see' red cells | ||
| + | #*Use the numbers in the table shown here to calculate the normalized mCherry:EGFP for these data with your template. | ||
| + | #**Confirm your answer with the teaching faculty to ensure you used the correct numbers in the calculation. | ||
| + | #When you are confident in your template and you are confident you know which numbers to use for your calculations, find the data for your conditions in the "Instructor FC plots" document and visually compare the fluorescent values between the variables tested. | ||
| + | #*Do you notice any apparent trends or differences in the data? | ||
| + | #Finally, it is time to crunch some numbers! | ||
| + | #*Open the xslx file named "Instructor FC spreadsheet" posted to the M2D7 Discussion page and locate the values for your conditions. | ||
| + | #Copy the values into your template spreadsheet. | ||
| + | #*Though you do not need to report both the median and mean values in your Systems engineering research article, you are required to complete both sets of calculations and post the results of both calculations to the M2D7 Discussion page on the wiki so your fellow classmates have ready access to the data. You may want to add on to your template so both calculations are completed for you simultaneously. | ||
| + | #For each of the twelve wells you should calculate the raw reporter expressions and a mCherry/EGFP normalized value. Then, for each intact/cut pair you can calculate an NHEJ value. | ||
| + | #Compare the calculated values. | ||
| + | #*Do the data support the trends or differences you noted when visually comparing the plots? | ||
| + | #Before you leave today, you should provide the teaching faculty with the information required by the table on the M2D7 Discussion page. | ||
| + | #*Rather than simply entering the data when you complete the calculations, please alert the teaching faculty when you have your values and she will either tell you to enter the information or will do it on your behalf. If more than one group edit at the same time data can be lost! | ||
==Navigation links== | ==Navigation links== | ||
Next day: [[20.109(S16):Journal Club II (Day8)| Journal Club II]] | Next day: [[20.109(S16):Journal Club II (Day8)| Journal Club II]] | ||
Previous day: [[20.109(S16):DNA repair assays (Day6)| DNA repair assays]] | Previous day: [[20.109(S16):DNA repair assays (Day6)| DNA repair assays]] | ||
Latest revision as of 13:19, 4 April 2016

Contents
Introduction
We hope that you’ll leave lab today with a sense of accomplishment, after inspecting your raw flow cytometry data and then calculating NHEJ repair values. Unfortunately or excitingly – depending on your perspective – it turns out in scientific research that the hard work is just beginning once the data is quantified! Interpreting the data and drawing (sometimes tentative) conclusions requires deep reading and thinking – a process that shouldn’t be rushed.
Now is the time to clearly understand the nature of the flow cytometry controls that you will examine. For each cell population, you prepared two DNA mixtures: (A) intact pMAX_mCherry plus intact pMAX_EGFP, and (B) intact pMAX_mCherry plus damaged pMAX_EGFP_MCS. The re-circularization of pMAX_EGFP_MCS (minus the nonsense insert) will be our most direct readout of how much repair occurred. In this simplest view, broken DNA = no fluorescent signal, and repaired DNA = green fluorescent signal. However, it is important to consider the possibility that one cell population simply took up more plasmid DNA than another. In more technical terms, what if the transfection efficiency is higher for one cell type than for the other, and therefore the repair rate artificially appears higher? To control for this, we co-transfected with intact pMAX_mCherry, which serves as a transfection control. Using the transfection control data, we will normalize for differences in DNA uptake. It is also important to think about the uptake of pMAX_mCherry compared to the uptake of pMAX_EGFP_MCS. What if the plasmids are taken up at different frequencies, or successfully expressed at different frequencies and/or signal intensities? Here is where the dual intact control is useful. It shows us the typical ratio of mCherry:EGFP uptake and expression, which we can use as a secondary normalization. Note that we use pMAX_EGFP as a control rather than pMAX_EGFP_MCS, because the latter will have very low expression that is not representative of the repaired construct: the nonsense insert separates the promoter and gene by too great a distance for robust expression.
Putting all of the above information together, the NHEJ repair frequency equation can be determined in three steps:
- (1) Raw F reporter expression = % cells positive for F x MFI(F) = "RAW"
- F can be "mCherry" or "EGFP" in our case
- MFI is mean fluorescence intensity or median fluorescence intensity
- (2) Normalized EGFP expression $ \qquad ={RAW_{EGFP} \over RAW_{mCherry}}\qquad $ = "NORM"
- (3) Reporter expression percent $ \qquad ={NORM_{EGFP.damaged} \over NORM_{EGFP.intact}}\qquad $ = NHEJ repair value
First, reporter expression for mCherry and EGFP alike will be calculated by multiplying percentage of positive cells by fluorescence intensity (FI). We have a choice of whether to use mean, geometric mean, or median fluorescence intensity. Median fluorescence is least susceptible to being influenced by a few outliers, while geometric mean is generally more appropriate for log scale data than arithmetic mean. For normally distributed populations, all three values should be pretty similar. In practice, we have found that while mean and median FI are very different values, after normalization the ultimate NHEJ repair values are quite similar, so we will use the mean value.
The second step is to calculate the ratio of EGFP to mCherry reporter expression for each sample. The final step is to divide the damaged-EGFP:mCherry ratio by the maximal possible “repair,” namely the intact-EGFP:mCherry ratio. Convince yourself that this parameter essentially provides the fraction of pMAX_EGFP_MCS repaired.
Most of your time today will be spent at the computer, quantifying your flow cytometry data. Use this time to get a strong start on the data analysis for your Systems engineering research article. On M2D9, we will use statistics to further analyze our data.
Protocols
Part 1: Paper discussion
We will start today with a discussion of the Dietlein et al. research article. In their research, the authors completed a screen to examine 1319 cancer-associated genes from 67 cell lines to identify cancer-cell specific mutations that are associated with DNA-PKcs dependence or addiction. A paradox exists in cancer as whole genome sequencing has revealed that the cells of many tumor types have mutations in genes necessary for DNA repair. These mutations are responsible for cells becoming cancerous, but are also detrimental because, just like normal cells, cancer cells must divide to survive. Thus, a cancer cell will develop an ‘addiction’ to a DNA repair pathway – specifically, a pathway different from the one with the mutation that caused the cell to generate a tumor. Recent cancer therapies seek to exploit this addiction by targeting the intact pathway used by the tumor cells to repair DNA damage due to intrinsic breaks that occur during replication. In addition, the effectiveness DNA damage induced by chemotherapy treatment may be enhanced by also disrupting the functional repair pathways of tumor cells. The review article by Shaheen et al. provides further information on repair pathway addiction as a target in cancer treatment.
Our paper discussion will be guided by all that you have learned about how to write a cohesive story that clearly reports the data and provides strong support for the conclusions made about the data. During the paper discussion, everyone is expected to participate - either by volunteering or by being called upon!
Introduction
Remember the key components of an introduction:
- What is the big picture?
- Is the importance of this research clear?
- Are you provided with the information you need to understand the research?
- Do the authors include a preview of the key results?
Results
Carefully examine the figures. First, read the captions and use the information to 'interpret' the data presented within the image. Second, read the text within the results section that describes the figure.
- Do you agree with the conclusion(s) reached by the authors?
- What controls are included and are they appropriate for the experiment performed?
- Are you convinced that the data are accurate and/or representative?
Discussion
Consider the following components of a discussion:
- Are the results summarized?
- Did the authors 'tie' the data together into a cohesive and well-interpreted story?
- Do the authors overreach when interpreting the data?
- Are the data linked back to the big picture from the introduction?
Part 2: Analyze flow cytometry data
In the previous laboratory session, you learned how the gates are established in flow cytometry. This very important step is necessary in enabling you to distinguish and count the specific cell populations within your samples. Today you will analyze the numerical data, or counts, that were collected for your transfection conditions based on the mCherry and EGFP gates.
Before you calculate the frequency of DNA repair that occurred in your samples, examine the data obtained in Spring 2015 to acquaint yourself with calculations discussed in prelab. The spreadsheet below shows a template used to calculate the NHEJ repair efficiency using the EGFP:BFP reporter system employed by students previous to this semester. Use the data in the spreadsheet to answer the questions below.

- To test yourself, use the numbers provided in the sample spreadsheet to calculate the NHEJ efficiency with the median fluorescent values by hand.
- Include your math in your notebook.
- First, you will create a template in Excel that will enable to quickly determine the values for your samples.
- Feel free to use the format of the sample NHEJ calculator.
- Enter the median values from the sample spreadsheet to test your template.
- Now let's look at the data collected using your conditions.
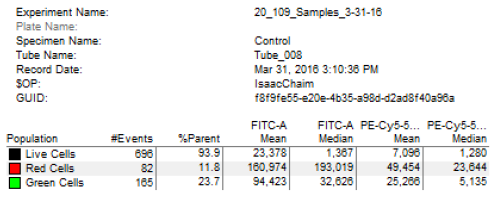 Flow cytometry plot statistics summary.
Flow cytometry plot statistics summary.
- Open the PDF posted to the M2D7 Discussion page named "Instructor FC plots" and the sample key named "Instructor FC sample key" and find the plot for sample #8 (M059K cells co-transfected with pMAX_mCherry and pMAX_EGFP). At the bottom of the page you should see a table similar to the one shown at the right.
- The values in this table are the counts that were measured for this sample. Consider the following:
- #Events = the number of cells counted based on the gate established (i.e. the number of red cells is based on the mCherry gate)
- %Parent = the percentage of cells in a given population (i.e. the number of red cells within the live cell population)
- FITC-A = filter used to 'see' green cells
- PE-Cy5-5... = filter used to 'see' red cells
- Use the numbers in the table shown here to calculate the normalized mCherry:EGFP for these data with your template.
- Confirm your answer with the teaching faculty to ensure you used the correct numbers in the calculation.
- When you are confident in your template and you are confident you know which numbers to use for your calculations, find the data for your conditions in the "Instructor FC plots" document and visually compare the fluorescent values between the variables tested.
- Do you notice any apparent trends or differences in the data?
- Finally, it is time to crunch some numbers!
- Open the xslx file named "Instructor FC spreadsheet" posted to the M2D7 Discussion page and locate the values for your conditions.
- Copy the values into your template spreadsheet.
- Though you do not need to report both the median and mean values in your Systems engineering research article, you are required to complete both sets of calculations and post the results of both calculations to the M2D7 Discussion page on the wiki so your fellow classmates have ready access to the data. You may want to add on to your template so both calculations are completed for you simultaneously.
- For each of the twelve wells you should calculate the raw reporter expressions and a mCherry/EGFP normalized value. Then, for each intact/cut pair you can calculate an NHEJ value.
- Compare the calculated values.
- Do the data support the trends or differences you noted when visually comparing the plots?
- Before you leave today, you should provide the teaching faculty with the information required by the table on the M2D7 Discussion page.
- Rather than simply entering the data when you complete the calculations, please alert the teaching faculty when you have your values and she will either tell you to enter the information or will do it on your behalf. If more than one group edit at the same time data can be lost!

Next day: Journal Club II
Previous day: DNA repair assays