Difference between revisions of "20.109(S22):M2D4"
Noreen Lyell (Talk | contribs) (→Protocols) |
Noreen Lyell (Talk | contribs) (→Part 4: Prepare psgRNA clones for sequencing analysis) |
||
| (18 intermediate revisions by one user not shown) | |||
| Line 5: | Line 5: | ||
==Introduction== | ==Introduction== | ||
| + | |||
| + | The CRISPRi system involves three genetic components: the pdCas9 plasmid (1 in image below), the psgRNA_target plasmid (2 in image below), and the targeted gene within the host genome (3 in image below). Though the targeted gene is native to the host genome, the plasmids must be transformed into the cell and maintained using antibiotic selection. Thus far in this module, we have discussed the CRISPRi plasmids as individual units, but now we will consider the system as a whole in the context of engineering gene expression. | ||
| + | |||
| + | [[Image:Fa20 M3D3 CRISPRi system.png|thumb|center|750px|'''Overview of CRISPRi system.''' The CRISPRi system consists of three genetic components: 1. an expression plasmid that encodes the pdCas9 protein that binds to DNA when complexed with sgRNA, 2. an expression plasmid that encodes the sgRNA that is complementary to the targeted sequence in the host genome, and 3. the targeted sequence in the host genome. Image generated using BioRender.]] | ||
| + | |||
| + | In the previous laboratory session, you performed the procedure used to generate the psgRNA_target plasmids. Today we will transform the CRISPRi system (pdCasd9 and psgRNA_target) is into ''E. coli''. Once transformed into the bacterial cells, the sgRNA_target and dCas9 are transcribed from the respective expression plasmids. As an overview, the promoter (pJ23119) driving expression of the sgRNA sequence in the gRNA_target plasmid is constitutively active. This means that transcription of the gRNA sequence specific to the target in the host genome is constitutive. Therefore, your sgRNA_target is always present in the MG1655 cells. In a mechanism that we will discuss in the next laboratory session, expression of dCas9 is controlled using an inducer molecule. | ||
| + | <br style="clear:both;"/> | ||
==Protocols== | ==Protocols== | ||
| Line 12: | Line 19: | ||
Our communication instructor, Dr. Prerna Bhargava, will join us today for a discussion on preparing a journal club presentation. | Our communication instructor, Dr. Prerna Bhargava, will join us today for a discussion on preparing a journal club presentation. | ||
| − | === | + | ===Part 2: Mini-prep pgRNA_target clones=== |
| − | The | + | The procedure for DNA isolation using small volumes is commonly termed "mini-prep," which distinguishes it from a “maxi-prep” that involves a larger volume of cells and additional steps of purification. The overall goal of each prep is the same -- to separate the plasmid DNA from the chromosomal DNA and cellular debris. In the traditional mini-prep protocol, the media is removed from the cells by centrifugation. The cells are resuspended in a solution that contains Tris to buffer the cells and EDTA to bind divalent cations in the lipid bilayer, thereby weakening the cell envelope. A solution of sodium hydroxide and sodium dodecyl sulfate (SDS) is then added. The base denatures the DNA, both chromosomal and plasmid, while the detergent dissolves the cellular proteins and lipids. The pH of the solution is returned to neutral by adding a mixture of acetic acid and potassium acetate. At neutral pH the SDS precipitates from solution, carrying with it the dissolved proteins and lipids. In addition, the DNA strands renature at neutral pH. The chromosomal DNA, which is much longer than the plasmid DNA, renatures as a tangle that gets trapped in the SDS precipitate. The plasmid DNA renatures normally and stays in solution. Thus plasmid DNA got effectively separated from chromosomal DNA and proteins and lipids of the cell. |
| − | + | Today you will use a kit that relies on a column to collect the renatured plasmid DNA. The silica gel column interacts with the DNA while allowing contaminants to pass through the column. This interaction is aided by chaotropic salts and ethanol, which are added in the buffers. The ethanol dehydrates the DNA backbone allowing the chaotropic salts to form a salt bridge between the silica and the DNA. | |
| − | + | For timing reasons, two colonies from the spread plates you prepared in the previous laboratory session were inoculated into LB/Amp and grown overnight at 37°C on a rotator. | |
| + | #Retrieve your two cultures from the font laboratory bench. Label two eppendorf tubes to reflect your samples (psgRNA_target#1 and psgRNA_target#2). | ||
| + | #Vortex the bacterial cultures and pour ~1.5 mL of each into the appropriate eppendorf tube. [[Image:Removing cells.jpg|thumb|right|200px|'''Diagram showing how to aspirate the supernatant.''' Be careful to remove as few cells as possible.]] | ||
| + | #Balance the tubes in the microfuge, spin them at maximum speed for 2 min, and remove the supernatants with the vacuum aspirator. | ||
| + | #Pour another 1.5 mL of each culture into the appropriate eppendorf tube (add the culture to the pellet previously collected), and repeat the spin step. Repeat until you use up the entire volume of culture. | ||
| + | #Resuspend each cell pellet in 250 μL buffer P1. | ||
| + | #*Buffer P1 contains RNase so that we collect only our nucleic acid of interest, DNA. | ||
| + | #Add 250 μL of buffer P2 to each tube, and mix by inversion until the suspension is homogeneous. About 4-6 inversions of the tube should suffice. You may incubate here for '''up to 5 minutes, but not more'''. | ||
| + | #*Buffer P2 contains sodium hydroxide for lysing. | ||
| + | #Add 350 μL buffer N3 to each tube, and mix '''immediately''' by inversion (4-10 times). | ||
| + | #*Buffer N3 contains acetic acid, which will cause the chromosomal DNA to messily precipitate; the faster you invert, the more homogeneous the precipitation will be. | ||
| + | #*Buffer N3 also contains a chaotropic salt in preparation for the silica column purification. | ||
| + | #Centrifuge for 10 minutes at maximum speed. Note that you will be saving the '''supernatant''' after this step. | ||
| + | #*Meanwhile, prepare 2 labeled QIAprep columns, one for each candidate clone, and 2 trimmed eppendorf tubes for the final elution step. | ||
| + | #Transfer the entire supernatant to the column and centrifuge for 1 min. Discard the eluant into a tube labeled ''''Qiagen waste'.''' | ||
| + | #Add 0.5 mL PB to each column, then spin for 1 min and discard the eluant into the Qiagen waste tube. | ||
| + | #Next wash with 0.75 mL PE, with a 1 min spin step as usual. Discard the ethanol in the Qiagen waste tube. | ||
| + | #After removing the PE, spin the mostly dry column for 1 more minute. | ||
| + | #*It is important to remove all traces of ethanol, as they may interfere with subsequent work with the DNA. | ||
| + | #Transfer each column insert (blue) to the trimmed eppendorf tube you prepared (cut off lid). | ||
| + | #Add 30 μL of distilled H<sub>2</sub>O pH ~8 to the top center of the column, wait 1 min, and then spin 1 min to collect your DNA. | ||
| + | #Cap the trimmed tube or transfer elution to new eppendorf tube. | ||
| + | #Alert the Instructor when you are ready to measure the concentration of DNA in your mini-prep. | ||
| + | <font color = #4a9152 >'''In your laboratory notebook,'''</font color> complete the following: | ||
| + | *Record the concentration for each of the mini-prep you prepared. | ||
| + | *Record the 260/280 ratio for of the mini-preps you prepared. What does this value indicate about the purity of the DNA in your mini-preps? | ||
| − | ===Part | + | ===Part 3: Transform CRIPSRi system into MG1655 ''E. coli'' cells=== |
| − | + | During transformation, a plasmid enters a competent bacterium, then replicates and expresses the encoded genes. In a co-transformation, the goal is to transform each bacterial cell with two plasmids that each encode a different set of genes. Following the co-transformation procedure, a mixed population of cells exists as shown in the figure to the right: some cells only contain the plasmid that carries the resistance cassette for antibiotic A (blue cells), some cells only contain the plasmid that encodes the resistance cassette for antibiotic B (red cells), and some cells contain both plasmids (purple cells). Because the agar plate used for selection contains both antibiotic A and antibiotic B, only bacterial cells that harbor both plasmids survive and reproduce to form a colony. | |
| − | + | [[Image:Fa20 M3D3 cotransformation schematic.png|thumb|right|550px|'''Schematic of bacterial co-transformation.''' Bacterial cells that harbor both plasmids (purple cells) are selected for using an agar plate that contain antibiotics.]]In the CRISPRi system, a gene on the psgRNA_target expression plasmid encodes an ampicillin-resistance cassette and a gene on the pdCas9 plasmid encodes a chloramphenicol-resistance cassette. Thus, only a co-transformed bacterium will grow on agar plates containing the antibiotics ampicillin and chloramphenicol. | |
| − | + | Most bacteria do not usually exist in a “transformation ready” state, referred to as competence. Instead bacterial cells are incubated with CaCl<sub>2</sub> to promote competency by making the cells permeable to plasmid DNA uptake. Competent cells are extremely fragile and should be handled gently, specifically the cells should be kept cold and not vortexed. The transformation procedure is efficient enough for most lab purposes, with efficiencies as high as 10<sup>9</sup> transformed cells per microgram of DNA, but it is important to realize that even with high efficiency cells only 1 DNA molecule in about 10,000 is successfully transformed. | |
| + | You will transform each of your mini-prepped psgRNA_target plasmids with the pdCas9 plasmid into ''E. coli'' MG1655, which is the strain we will use to examine the effect of your approach on either ethanol or acetate production. | ||
| − | + | #Label two 1.5 mL eppendorf tubes with your team information and clone designation (psgRNA_target#1 and psgRNA_target#2). | |
| + | #*'''Please note:''' you will add one of your candidate clone plasmid mini-preps to each tube and the pdCas9 to both tubes! | ||
| + | #Acquire an aliquot of the pdCas9 mini-prep (prepared by the Instructors) and of the competent MG1655 ''E. coli'' cells from the front laboratory bench. | ||
| + | #Pipet 100 μL of the MG1655 competent cells into each labeled eppendorf tube. | ||
| + | #*'''Remember:''' it is important to keep the competent cells on ice! Also, avoid over pipetting and vortexing! | ||
| + | #Add 5 μL of the pdCas9 mini-prep to each tube. | ||
| + | #Add 5 μL of each pgRNA candidate clone mini-prep to the appropriate eppendorf tube. | ||
| + | #Incubate your co-transformation mixes on ice for 30 min. | ||
| + | #Carry your ice bucket with your co-transformations to the heat block at the front laboratory bench. | ||
| + | #*Be sure you also take your timer. | ||
| + | #Transfer the tubes with your co-transformations to the heat block set to 42 °C and incubate for '''exactly''' 45 sec. | ||
| + | #Remove your co-transformations from the heat block and '''immediately''' put them back in the ice bucket, then incubate for 2 min. | ||
| + | #Pipet 500 μL of pre-warmed SOC media into each co-transformation. | ||
| + | #Move your co-transformations to the 37 °C incubator and carefully place them on the nutator (secure your tubes by sliding them under the rubberband). | ||
| + | #Incubate co-transformations for 1 h. | ||
| + | #*Complete Part 4 during this incubation! | ||
| + | #Retrieve your co-transformations from the incubator and alert the teaching faculty that you are ready to plate your samples. | ||
| + | #Plate 100μL of each co-transformation onto an appropriately labeled LB+Amp+Cam agar plate. | ||
| + | #*The teaching faculty will demonstrate how you should 'spread' your co-transformation onto the LB+Amp+Cam agar plates. You should include this procedure in your laboratory notebook. | ||
| + | #Incubate your spread plates in the 37 °C incubator for ~18 hr. | ||
| − | + | ===Part 4: Prepare psgRNA clones for sequencing analysis=== | |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| + | DNA sequencing will be used to confirm that the sgRNA_target sequence that was inserted into the expression plasmid is correct. The invention of automated sequencing machines has made sequence determination a relatively fast and inexpensive process. The method for sequencing DNA is not new but automation of the process is recent, developed in conjunction with the massive genome sequencing efforts of the 1990s and 2000s. At the heart of sequencing reactions is chemistry worked out by Fred Sanger in the 1970s which uses dideoxynucleotides, or chain-terminating bases. These chain-terminating bases can be added to a growing chain of DNA but cannot be further extended. Performing four reactions, each with a different chain-terminating base, generates fragments of different lengths ending at G, A, T, or C. The fragments, once separated by size, reflect the DNA sequence due to the presence of fluorescent dyes, one color linked to each dideoxy-base. The four colored fragments can be passed through capillaries to a computer that can read the output and trace the color intensities detected. | ||
| + | [[Image:Fa20 M3D2 sanger sequencing.png|thumb|center|700px|'''Principles of Sanger sequencing.''' A. Chain-terminating bases are used to halt the DNA synthesis reaction at different lengths and attach a fluorophore that is used to determine the sequence of the DNA strand. B. The sequence of the DNA strand is determined using the fluorescent signature associated with each length of DNA in the reaction, this is visualized as a chromatogram.]] | ||
| + | Just as amplification reactions require a primer for initiation, primers are also needed for sequencing reactions. Legible readout of the gene typically begins about 40-50 bp downstream of the primer site, and continues for ~1000 bp at most. Thus, multiple primers must be used to fully view genes > 1 kb in size. Though the target sequence for your gRNA is shorter than 1000 bp, we will sequence with both a forward and reverse primer to double-check that the sequence is correct (''i.e.'' free of unwanted mutations). | ||
| + | The sequences for the primers you will use to confirm your sgRNA_target insert are below: | ||
| − | + | <center> | |
| − | + | {| border="1" | |
| − | + | ! Primer | |
| − | + | ! Sequence | |
| − | + | |- | |
| − | + | | sgRNA confirmation forward primer | |
| − | + | | 5' - GGG TTA TTG TCT CAT GAG CGG ATA CAT ATT TG - 3' | |
| − | + | |- | |
| − | + | | sgRNA confirmation reverse primer | |
| − | + | | 5' - CGC GGC CTT TTT ACG GTT C - 3' | |
| − | + | |- | |
| − | + | |} | |
| − | + | </center> | |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | Because you will examine the sgRNA_target sequence in your psgRNA_target plasmids using both a forward and a reverse primer, '''you will need to prepare two reactions for each mini-prep'''. Thus you will have a total of four sequencing reactions. For each reaction, combine the following reagents in a clearly labeled eppendorf tube: | |
| − | + | *12 μL nuclease-free water | |
| − | ''' | + | *8 μL of your plasmid DNA candidate |
| − | + | *10 μL of the primer stock from the front laboratory bench (the stock concentration is 5 pmol/μL) | |
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | ||
| − | + | <font color = #4a9152 >'''In your laboratory notebook,'''</font color> complete the following: | |
| − | + | *Calculate the quantity (in ng) of DNA in each of the sequencing reactions. | |
| + | *Calculate the final concentration of sequencing primer in each reaction. | ||
==Reagents list== | ==Reagents list== | ||
| + | *QIAprep Spin Miniprep Kit (from Qiagen) | ||
| + | **buffer P1 | ||
| + | **buffer P2 | ||
| + | **buffer N3 | ||
| + | **buffer PB | ||
| + | **buffer PE | ||
| + | *pdCas9 (concentration: 0.05 μg / μL ) (a gift from Prather Laboratory) | ||
| + | *Chemically competent ''E. coli'' MG1655 (genotype: ''F- lambda- ilvG- rfb-50 rph-1'') | ||
| + | *SOC medium: 2% tryptone, 0.5% yeast extract, 10 mM NaCl, 2.5 mM KCl, 10 mM MgCl2, 10 mM MgSO4, and 20 mM glucose | ||
| + | *LB+Amp+Cam plates | ||
| + | **Luria-Bertani (LB) broth: 1% tryptone, 0.5% yeast extract, and 1% NaCl | ||
| + | **Plates prepared by adding 1.5% agar, 100 μg/mL ampicillin (Amp), and 34 μg/mL chloramphenicol (Cam) to LB | ||
==Navigation links== | ==Navigation links== | ||
Next day: [[20.109(S22):M2D5 |Prepare for induction of CRISPRi system]] <br> | Next day: [[20.109(S22):M2D5 |Prepare for induction of CRISPRi system]] <br> | ||
Previous day: [[20.109(S22):M2D3 |Clone psgRNA expression plasmid]] <br> | Previous day: [[20.109(S22):M2D3 |Clone psgRNA expression plasmid]] <br> | ||
Latest revision as of 21:09, 24 January 2022

Contents
Introduction
The CRISPRi system involves three genetic components: the pdCas9 plasmid (1 in image below), the psgRNA_target plasmid (2 in image below), and the targeted gene within the host genome (3 in image below). Though the targeted gene is native to the host genome, the plasmids must be transformed into the cell and maintained using antibiotic selection. Thus far in this module, we have discussed the CRISPRi plasmids as individual units, but now we will consider the system as a whole in the context of engineering gene expression.

In the previous laboratory session, you performed the procedure used to generate the psgRNA_target plasmids. Today we will transform the CRISPRi system (pdCasd9 and psgRNA_target) is into E. coli. Once transformed into the bacterial cells, the sgRNA_target and dCas9 are transcribed from the respective expression plasmids. As an overview, the promoter (pJ23119) driving expression of the sgRNA sequence in the gRNA_target plasmid is constitutively active. This means that transcription of the gRNA sequence specific to the target in the host genome is constitutive. Therefore, your sgRNA_target is always present in the MG1655 cells. In a mechanism that we will discuss in the next laboratory session, expression of dCas9 is controlled using an inducer molecule.
Protocols
Part 1: Participate in Communication Lab workshop
Our communication instructor, Dr. Prerna Bhargava, will join us today for a discussion on preparing a journal club presentation.
Part 2: Mini-prep pgRNA_target clones
The procedure for DNA isolation using small volumes is commonly termed "mini-prep," which distinguishes it from a “maxi-prep” that involves a larger volume of cells and additional steps of purification. The overall goal of each prep is the same -- to separate the plasmid DNA from the chromosomal DNA and cellular debris. In the traditional mini-prep protocol, the media is removed from the cells by centrifugation. The cells are resuspended in a solution that contains Tris to buffer the cells and EDTA to bind divalent cations in the lipid bilayer, thereby weakening the cell envelope. A solution of sodium hydroxide and sodium dodecyl sulfate (SDS) is then added. The base denatures the DNA, both chromosomal and plasmid, while the detergent dissolves the cellular proteins and lipids. The pH of the solution is returned to neutral by adding a mixture of acetic acid and potassium acetate. At neutral pH the SDS precipitates from solution, carrying with it the dissolved proteins and lipids. In addition, the DNA strands renature at neutral pH. The chromosomal DNA, which is much longer than the plasmid DNA, renatures as a tangle that gets trapped in the SDS precipitate. The plasmid DNA renatures normally and stays in solution. Thus plasmid DNA got effectively separated from chromosomal DNA and proteins and lipids of the cell.
Today you will use a kit that relies on a column to collect the renatured plasmid DNA. The silica gel column interacts with the DNA while allowing contaminants to pass through the column. This interaction is aided by chaotropic salts and ethanol, which are added in the buffers. The ethanol dehydrates the DNA backbone allowing the chaotropic salts to form a salt bridge between the silica and the DNA.
For timing reasons, two colonies from the spread plates you prepared in the previous laboratory session were inoculated into LB/Amp and grown overnight at 37°C on a rotator.
- Retrieve your two cultures from the font laboratory bench. Label two eppendorf tubes to reflect your samples (psgRNA_target#1 and psgRNA_target#2).
- Vortex the bacterial cultures and pour ~1.5 mL of each into the appropriate eppendorf tube.
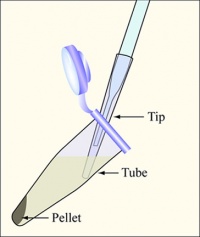 Diagram showing how to aspirate the supernatant. Be careful to remove as few cells as possible.
Diagram showing how to aspirate the supernatant. Be careful to remove as few cells as possible.
- Balance the tubes in the microfuge, spin them at maximum speed for 2 min, and remove the supernatants with the vacuum aspirator.
- Pour another 1.5 mL of each culture into the appropriate eppendorf tube (add the culture to the pellet previously collected), and repeat the spin step. Repeat until you use up the entire volume of culture.
- Resuspend each cell pellet in 250 μL buffer P1.
- Buffer P1 contains RNase so that we collect only our nucleic acid of interest, DNA.
- Add 250 μL of buffer P2 to each tube, and mix by inversion until the suspension is homogeneous. About 4-6 inversions of the tube should suffice. You may incubate here for up to 5 minutes, but not more.
- Buffer P2 contains sodium hydroxide for lysing.
- Add 350 μL buffer N3 to each tube, and mix immediately by inversion (4-10 times).
- Buffer N3 contains acetic acid, which will cause the chromosomal DNA to messily precipitate; the faster you invert, the more homogeneous the precipitation will be.
- Buffer N3 also contains a chaotropic salt in preparation for the silica column purification.
- Centrifuge for 10 minutes at maximum speed. Note that you will be saving the supernatant after this step.
- Meanwhile, prepare 2 labeled QIAprep columns, one for each candidate clone, and 2 trimmed eppendorf tubes for the final elution step.
- Transfer the entire supernatant to the column and centrifuge for 1 min. Discard the eluant into a tube labeled 'Qiagen waste'.
- Add 0.5 mL PB to each column, then spin for 1 min and discard the eluant into the Qiagen waste tube.
- Next wash with 0.75 mL PE, with a 1 min spin step as usual. Discard the ethanol in the Qiagen waste tube.
- After removing the PE, spin the mostly dry column for 1 more minute.
- It is important to remove all traces of ethanol, as they may interfere with subsequent work with the DNA.
- Transfer each column insert (blue) to the trimmed eppendorf tube you prepared (cut off lid).
- Add 30 μL of distilled H2O pH ~8 to the top center of the column, wait 1 min, and then spin 1 min to collect your DNA.
- Cap the trimmed tube or transfer elution to new eppendorf tube.
- Alert the Instructor when you are ready to measure the concentration of DNA in your mini-prep.

In your laboratory notebook, complete the following:
- Record the concentration for each of the mini-prep you prepared.
- Record the 260/280 ratio for of the mini-preps you prepared. What does this value indicate about the purity of the DNA in your mini-preps?
Part 3: Transform CRIPSRi system into MG1655 E. coli cells
During transformation, a plasmid enters a competent bacterium, then replicates and expresses the encoded genes. In a co-transformation, the goal is to transform each bacterial cell with two plasmids that each encode a different set of genes. Following the co-transformation procedure, a mixed population of cells exists as shown in the figure to the right: some cells only contain the plasmid that carries the resistance cassette for antibiotic A (blue cells), some cells only contain the plasmid that encodes the resistance cassette for antibiotic B (red cells), and some cells contain both plasmids (purple cells). Because the agar plate used for selection contains both antibiotic A and antibiotic B, only bacterial cells that harbor both plasmids survive and reproduce to form a colony.
Most bacteria do not usually exist in a “transformation ready” state, referred to as competence. Instead bacterial cells are incubated with CaCl2 to promote competency by making the cells permeable to plasmid DNA uptake. Competent cells are extremely fragile and should be handled gently, specifically the cells should be kept cold and not vortexed. The transformation procedure is efficient enough for most lab purposes, with efficiencies as high as 109 transformed cells per microgram of DNA, but it is important to realize that even with high efficiency cells only 1 DNA molecule in about 10,000 is successfully transformed.
You will transform each of your mini-prepped psgRNA_target plasmids with the pdCas9 plasmid into E. coli MG1655, which is the strain we will use to examine the effect of your approach on either ethanol or acetate production.
- Label two 1.5 mL eppendorf tubes with your team information and clone designation (psgRNA_target#1 and psgRNA_target#2).
- Please note: you will add one of your candidate clone plasmid mini-preps to each tube and the pdCas9 to both tubes!
- Acquire an aliquot of the pdCas9 mini-prep (prepared by the Instructors) and of the competent MG1655 E. coli cells from the front laboratory bench.
- Pipet 100 μL of the MG1655 competent cells into each labeled eppendorf tube.
- Remember: it is important to keep the competent cells on ice! Also, avoid over pipetting and vortexing!
- Add 5 μL of the pdCas9 mini-prep to each tube.
- Add 5 μL of each pgRNA candidate clone mini-prep to the appropriate eppendorf tube.
- Incubate your co-transformation mixes on ice for 30 min.
- Carry your ice bucket with your co-transformations to the heat block at the front laboratory bench.
- Be sure you also take your timer.
- Transfer the tubes with your co-transformations to the heat block set to 42 °C and incubate for exactly 45 sec.
- Remove your co-transformations from the heat block and immediately put them back in the ice bucket, then incubate for 2 min.
- Pipet 500 μL of pre-warmed SOC media into each co-transformation.
- Move your co-transformations to the 37 °C incubator and carefully place them on the nutator (secure your tubes by sliding them under the rubberband).
- Incubate co-transformations for 1 h.
- Complete Part 4 during this incubation!
- Retrieve your co-transformations from the incubator and alert the teaching faculty that you are ready to plate your samples.
- Plate 100μL of each co-transformation onto an appropriately labeled LB+Amp+Cam agar plate.
- The teaching faculty will demonstrate how you should 'spread' your co-transformation onto the LB+Amp+Cam agar plates. You should include this procedure in your laboratory notebook.
- Incubate your spread plates in the 37 °C incubator for ~18 hr.
Part 4: Prepare psgRNA clones for sequencing analysis
DNA sequencing will be used to confirm that the sgRNA_target sequence that was inserted into the expression plasmid is correct. The invention of automated sequencing machines has made sequence determination a relatively fast and inexpensive process. The method for sequencing DNA is not new but automation of the process is recent, developed in conjunction with the massive genome sequencing efforts of the 1990s and 2000s. At the heart of sequencing reactions is chemistry worked out by Fred Sanger in the 1970s which uses dideoxynucleotides, or chain-terminating bases. These chain-terminating bases can be added to a growing chain of DNA but cannot be further extended. Performing four reactions, each with a different chain-terminating base, generates fragments of different lengths ending at G, A, T, or C. The fragments, once separated by size, reflect the DNA sequence due to the presence of fluorescent dyes, one color linked to each dideoxy-base. The four colored fragments can be passed through capillaries to a computer that can read the output and trace the color intensities detected.

Just as amplification reactions require a primer for initiation, primers are also needed for sequencing reactions. Legible readout of the gene typically begins about 40-50 bp downstream of the primer site, and continues for ~1000 bp at most. Thus, multiple primers must be used to fully view genes > 1 kb in size. Though the target sequence for your gRNA is shorter than 1000 bp, we will sequence with both a forward and reverse primer to double-check that the sequence is correct (i.e. free of unwanted mutations).
The sequences for the primers you will use to confirm your sgRNA_target insert are below:
| Primer | Sequence |
|---|---|
| sgRNA confirmation forward primer | 5' - GGG TTA TTG TCT CAT GAG CGG ATA CAT ATT TG - 3' |
| sgRNA confirmation reverse primer | 5' - CGC GGC CTT TTT ACG GTT C - 3' |
Because you will examine the sgRNA_target sequence in your psgRNA_target plasmids using both a forward and a reverse primer, you will need to prepare two reactions for each mini-prep. Thus you will have a total of four sequencing reactions. For each reaction, combine the following reagents in a clearly labeled eppendorf tube:
- 12 μL nuclease-free water
- 8 μL of your plasmid DNA candidate
- 10 μL of the primer stock from the front laboratory bench (the stock concentration is 5 pmol/μL)
In your laboratory notebook, complete the following:
- Calculate the quantity (in ng) of DNA in each of the sequencing reactions.
- Calculate the final concentration of sequencing primer in each reaction.
Reagents list
- QIAprep Spin Miniprep Kit (from Qiagen)
- buffer P1
- buffer P2
- buffer N3
- buffer PB
- buffer PE
- pdCas9 (concentration: 0.05 μg / μL ) (a gift from Prather Laboratory)
- Chemically competent E. coli MG1655 (genotype: F- lambda- ilvG- rfb-50 rph-1)
- SOC medium: 2% tryptone, 0.5% yeast extract, 10 mM NaCl, 2.5 mM KCl, 10 mM MgCl2, 10 mM MgSO4, and 20 mM glucose
- LB+Amp+Cam plates
- Luria-Bertani (LB) broth: 1% tryptone, 0.5% yeast extract, and 1% NaCl
- Plates prepared by adding 1.5% agar, 100 μg/mL ampicillin (Amp), and 34 μg/mL chloramphenicol (Cam) to LB
Next day: Prepare for induction of CRISPRi system